Meaning of Genetic Code:
The genetic code may be defined as the exact sequence of DNA nucleotides
read as three letter words or codons, that determines the sequence of amino acids in
protein synthesis. In other words, the genetic code is the set of rules by which information
encoded in genetic material DNA or RNA sequences) is translated into proteins (amino
acid sequences) by living cells.
It is already known that DNA is a master molecule of a cell that
initiates, guides , regulates and control the process of protein synthesis. To perform this
complicated function, it must carry the requisite information for protein synthesis.
Obviously this information has to be verily located in DNA itself. The site for storing this
information lies in the sequence of nucleotides. (Nitrogen base pairs). As evidenced by
Yanisfski and Sarabahi(1964)
About 20 different types of amino acids are involved in the process of
protein synthesis .DNA molecule has four types of nitrogen bases to identify these 20
different types of amino acids. Question arises then, how it is possible that 20 types of
amino acids are encoded by 4 types of nitrogen base pairs?
According to F.H.C. Crick this information is stored in the form of
coded language(cryptogram) called as genetic code that contains code words(codon) each
one specifying (representing) specific amino acid. Genetic code therefore is a collection of
base sequences that correspond to each amino acid.
A single nitrogen base in a codon ( singlet codon) will encode for only four different types
of amino acids a combination of two nitrogen base (doublet codon) will specify only 16
different types of amino acids. A combination of three nitrogen bases (triplet codon) will
specify 64 different types of amino acids. Hence G.Gamov (1954) suggested that in a
codon there must be a combination of these consecutive nitrogen bases that will be
sufficient to specify 20 different types of amino acids.
Thus there would be 64 different codons (code words) in dictionary of genetic
code and that each code word has to be triplet codon. Every three consecutive nucleotides
in DNA will constitute a triplet codon. Genetic code is triplet code, was evidenced first by
Crick (1961) using ‘ frameshift mutation” . however M.Nirenberg and Matthaei were
able to synthesize artificial m-RNA which contained only one type of nitrogen base i.e
Uracil (homopolymerize).
This synthetic poly-U sequence was transferred to protein synthesizing
enzymes. A small polypeptide molecule was produced by linking of phenyl Alanine
molecules. This explains that UUU codes for phenyl Alanine . Later different
photopolymer codon were deciphered. Codons formed by two or more bases were also
tried.
Dr. Har Go bind Khorana advised a technique for artificially synthesizing m RNA with repeated sequence of known nucleotides. By using synthetic DNA, Dr. Khorana prepared chains of polynucleotide’s with known repeated sequences of two or
three nucleotides,
Eg-CUC UCU CUC UCU.
This resulted in formation of polypeptide chain having two different amino
acids place alternatively (leucine and Serine). Similarly polypeptide chain with these
nitrogen base repeats gave polypeptide chain with only one amino acids, eg- CUA CUA
CUA CUA(leucine). Later SE vero Ochoa established that the enzyme 9polynucleotide
phosphorylase) was also helpful in polymerizing RNA with defined sequences in a
template –independent manner. Finally Nirenberg ,Mathai and Ochoa deciphered all
the 64 codons in the dictionary of genetic code.
The main points related to genetic code are given below:
1. The genetic code is ‘read’ in triplets of bases called codons.
2. In a triplet code, three RNA bases code for one amino acid.
3. There are 64 codons which correspond to 20 amino acids and to signals for the
initiation and termination of transcription.
4. The code uses codons to make the amino acids that, in turn, constitute proteins.
5. Each triplet [codon] specifies one amino acid in a protein structure or a start signal
or stop signal in protein synthesis.
6. The code establishes the relationship between the sequence of bases in nucleic acids
(DNA and the complementary RNA) and the sequence of amino acids in proteins.
7. The code explains the mechanism by which genetic information is stored in living
organisms.
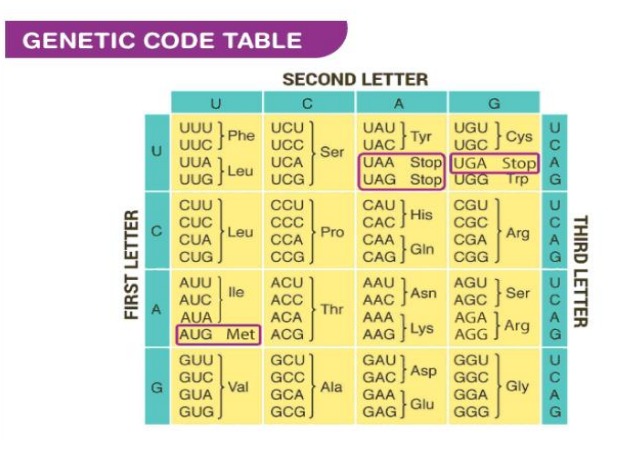
Types of Codon:
The genetic code consists of 64 triplets of nucleotides. These triplets are called
codons. With three exceptions, each codon encodes for one of the 20 amino acids used in
the synthesis of proteins. This produces some redundancy in the code.
Most of the amino acids are encoded by more than one codon. One codon
that is AUG serves two related functions. It signals the start of translation and codes for
the incorporation of the amino acid Methionine (Met) into the growing polypeptide chain.
The codons are of two type as follows:
(1) Sense codons
(2) Signal codons.
These are defined below:
1. Sense Codon:
Those codons that code for amino acids are called sense codons. There are 61 sense
codons in the genetic code which code for 20 amino acids.
2. Signal Codons:
Those codons that code for signals during protein synthesis are known as signal codons.
There are four codons which code for signal. These are AUG, UAA, UAG and UGA.
Signal codons are of two types
(i) Start codons,
(ii) Stop codons.
(i) Start Codons:
The codon which starts the translation process is known as start codon. It
is also known as initiation codon because it initiates the synthesis of polypeptide chain.
Example of this codon is AUG. This codon also codes for the amino acid methionine. In
some cases, valine (GUG) codes for start signal. In eukaryotes, the starting amino acid is
methionine, while in prokaryotes it is N-formyl methionine.
(ii) Stop Codons:
Those codons that provide signal for termination of polypeptide chain
are known as stop codons. These codons are also known as termination codons because
they provide signal for the termination and release of polypeptide chain. Examples of stop
codons are UAA, UAG and UGA. Since stop signal codons do not code for any amino
acid they were earlier called as non-sense codons. Signals of stop or termination codons
are read by proteins called release factors. Stop signals are not read by tRNA molecules.
Characteristics of Genetic Code:
Genetic code has some important characteristics.
1. The genetic code is triplet
2. Genetic code has distinct polarity
3. Genetic code is non-overlapping
4. The Code is Comma less
5. The Code has degeneracy (Redundant)
6. The Code is Universal
7. The Code is Non-ambiguous
8. Initiation codon and termination codon
9. Codon and anticodon
These are briefly discussed below:
1. The Code is Triplet:
The genetic code is triplet. The triplet code has 64 codons which are
sufficient to code for 20 amino acids and also for start and stop signals in the synthesis of
polypeptide chain. In a triplet code three RNA bases code for one amino acid.
The sequence of three consecutive bases constitutes codon, which specifies one particular
amino acid. Base sequence in a codon is always in 5’ 3’ direction. In every living
organism genetic code is triplet code.
2.Genetic code has distinct polarity:
Genetic code shows difinte plarity. i.e. direction. It, therefore is always read in 5’ 3’
direction and not in 3’ 5’ direction. Otherwise message will change e.g. 5 AUG 3
3.Genetic code is non-overlapping:
Code is non overlapping i.e. each single base is a part of only one codon. Adjacent
codons do not overlap .if non-overlapping ,then with 6 consecutive bases only two amino
acids molecules will be in chain. Had it been overlapping type, with 6 bases there would
be 4 amino acid molecules in a chain. Experimental evidence is in favor of non overlapping nature.
If mutation of one base into another leads in alteration of one amino acid only, it
indicates that the code is non-overlapping. Mutation experiments with TMV gave similar
results which indicated that the code is non-overlapping.
4. The Code is Comma less:
It is believed that the genetic code is comma less. In other words, the
codons are continuous and there are no demarcation lines between codons. Deletion of a
single base in a comma less code alters the entire sequence of amino acids after the Point
of deletion as given below.
The deletion of base C from Leucine will change the genetic message in the following
manner.
Experimental evidences also reveal that the genetic code is comma less. Khorana and coworkers have also demonstrated that the genetic code is comma less.
5. The Code has degeneracy (Redundant):
In most of the cases several codons code for the same amino acid. Only
two amino acids, viz. tryptophan and Methionine are coded by one codon each. Nine
amino acids are coded by two codons each, one amino acid [Isoleucine] by three codons,
five amino acids by 4 codons each, and three amino acids by 6 codons each
This multiple system of coding is known as degenerate or redundant code
system. Such system provides a protection to the organism against many harmful
mutations, because if one base of a codon is mutated, there are other codons which will
code for the same amino acid and there will be no alteration in the polypeptide chain.
The redundancy or degeneracy of the code is not random except for serine,
leucine and arginine. All codons coding for same amino acid are in the same box (except
above three). Thus the first two letters are GC in all four codons of Alanine and GC and
GU in all four codons of valine.
6.The Code is Universal:
The genetic code is almost universal. The same codons are assigned to the
same amino acids and to the same START and STOP signals in the vast majority of genes
in animals, plants, and microorganisms. However, some exceptions have been found. In
all living organisms the specific codon specifies same amino acid.
Eg: codon AUG always specifies amino acid methionine in all organisms from bacteria to
humans.
7. The Code is Non-ambiguous:
The genetic code has 64 codons. Out of these, 61 codons code for 20 different
amino acids. However, none of the codons codes for more than one amino acid. In other
words, each codon codes only for one amino acid. This clearly indicates that the genetic
code is non-ambiguous. In case of ambiguous code, one codon should code for more than
one amino acid. In the genetic code there is no ambiguity.
8. Initiation codon and termination codon:
AUG is always an initiation codon in every m-RNA. AUG codes for amino acid
Methionine. out of 64 codons three codons UAA,UAG and UGA are termination codon
which terminates or stops the process of elongation of polypeptide chain, as they do not
code for any amino acid.
9.Codon and anticodon:
Codon is a part of DNA
Eg: AUG is codon. It always represented as 5’ AUG 3’.
Anti codon is a part of t-RNA. It is always represented as 3’ UAC 5’.